



Post-instalación Ubuntu Server 24.04 para IA local: el servidor que trabaja en silencio
por Raúl UnzuéConfiguración Ubuntu Server para IA Local
Montar un servidor de IA local no termina cuando Ubuntu arranca por primera vez. Eso es solo el principio, y quien haya pasado por ello sabe que entre una instalación limpia y un sistema que realmente funciona hay una brecha que ningún tutorial cubre de principio a fin. Los drivers que no cargan solos, la GPU que aparece en lspci pero no en nvidia-smi, el ventilador que ruge a las tres de la madrugada porque nadie configuró las curvas térmicas. Detalles que se aprenden a golpes.
En el artículo anterior expliqué por qué elegí baremetal sobre Proxmox para este proyecto. La conclusión fue sencilla, menos capas, menos fricción, más rendimiento directo sobre el metal. Pero esa decisión tiene un precio, tú eres el responsable de cada ajuste que en un hipervisor se da por hecho. No hay interfaz web que te abstraiga del kernel, no hay snapshot que te salve de un sistema mal configurado.
Esta guía es lo que necesitas después de esa primera pantalla de login. Cubre la post-instalación completa de Ubuntu 24.04 Server orientada a inferencia local, la gestión de drivers NVIDIA, configuración térmica para operación continua, ajustes de energía que marcan la diferencia entre un servidor que consume 180W en idle y uno que consume 45W, y las optimizaciones específicas para que Ollama saque el máximo partido a tu hardware. El objetivo no es un servidor que funcione. Es un servidor que funcione bien, en silencio, las veinticuatro horas, sin que tengas que volver a tocarlo.
Actualización del sistema y paquetes base
Lo primero siempre es lo mismo, asegurarte de que el sistema arranca desde el estado más actualizado posible. Un Ubuntu recién instalado lleva semanas de actualizaciones acumuladas que incluyen parches de seguridad, actualizaciones del kernel y correcciones de drivers. No te saltes este paso.
# Actualizar lista de repositorios y paquetes
sudo apt update && sudo apt upgrade -y && sudo apt dist-upgrade -y
# Limpiar paquetes huérfanossudo apt autoremove -y && sudo apt autoclean
A continuación, instala las dependencias esenciales que necesitarás durante toda la guía:
sudo apt install -y \ build-essential \ git curl wget \
linux-headers-$(uname -r) \ dkms \ python3 python3-pip python3-venv \
htop nvtop btop \ lm-sensors fancontrol \ cpufrequtils \ nvme-cli \
net-tools openssh-server \ software-properties-common \
apt-transport-https ca-certificates gnupg
Si vas a gestionar el servidor por SSH desde otra máquina (lo cual tiene mucho sentido para un servidor headless), activa y configura SSH ahora: sudo systemctl enable --now ssh
Configurar hostname y zona horaria
# Dar un nombre propio al servidorsudo hostnamectl set-hostname jarvis
# Ajustar zona horaria (cambia según tu ubicación)
sudo timedatectl set-timezone Europe/Madridtimedatectl statusReinicia el sistema una vez para aplicar las actualizaciones del kernel antes de continuar:
sudo reboot
Drivers NVIDIA y stack CUDA completo
La PNY RTX Pro 2000 es una Blackwell profesional con 16 GB de VRAM ECC. Para sacarle el máximo partido en inferencia con Ollama necesitas el driver NVIDIA más reciente y el stack CUDA. Ubuntu Server 24.04 facilita mucho este proceso:
- Si durante la instalación de Ubuntu activaste los drivers privativos de terceros, es posible que ya tengas un driver NVIDIA instalado. Compruébalo con
nvidia-smiantes de continuar. Si ya funciona, salta al punto de instalación de CUDA toolkit.
# Ver qué driver recomienda el sistema para tu GPUubuntu-drivers devices
# Instalar el driver recomendado automáticamentesudo ubuntu-drivers autoinstall
# O instalar una versión concreta (p.ej. 570)
sudo apt install -y nvidia-driver-570
Instalación del CUDA Toolkit
# Añadir repositorio NVIDIA CUDA
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.debsudo apt update# Instalar CUDA toolkit
sudo apt install -y cuda-toolkit-12-6
# Añadir CUDA al PATH (añadir al .bashrc o .zshrc)
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
Reinicia y verifica que todo está en orden:
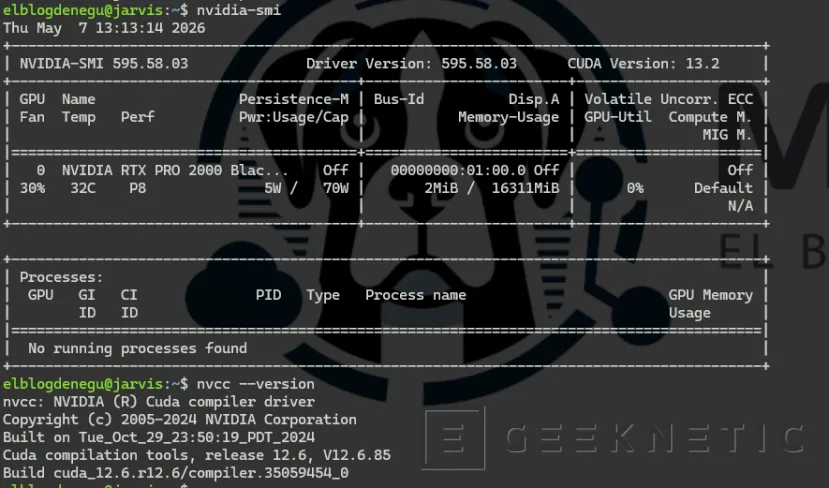
sudo reboot# Tras reiniciar:nvidia-sminvcc --versionLa salida de nvidia-smi debe mostrar la RTX Pro 2000 con sus 16 GB de VRAM y la versión del driver. Si aparece, el stack CUDA está operativo.
Optimizar la GPU para inferencia 24/7
Por defecto, la GPU entra en modo de bajo consumo cuando no tiene carga. Para un servidor que tiene que responder rápido, conviene fijar el modo de persistencia:
# Modo persistencia: la GPU no entra en sleep entre peticiones
sudo nvidia-smi -pm 1# Crea el directorio de configuración:
sudo mkdir -p /etc/systemd/system/nvidia-persistenced.service.d
# Crea el archivo de override:
sudo nano /etc/systemd/system/nvidia-persistenced.service.d/override.conf
# Pega exactamente esto:Ini, TOML[Install]WantedBy=multi-user.target
# Recarga y habilita:sudo systemctl daemon-reload
sudo systemctl enable nvidia-persistenced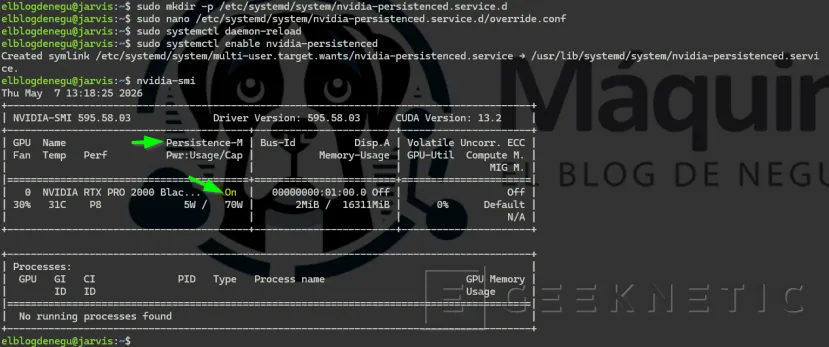
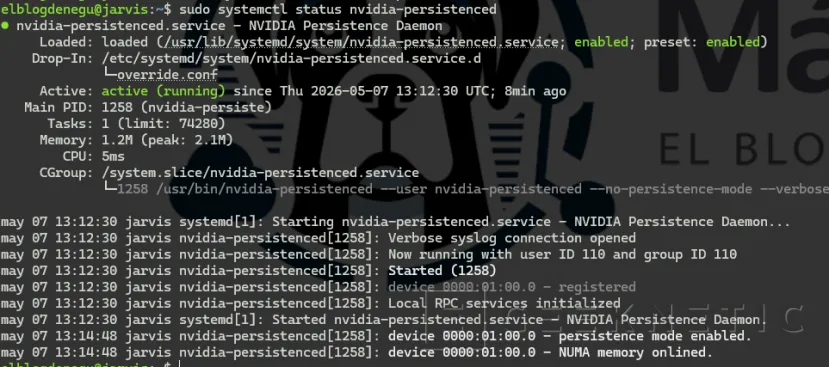
Podemos comprobar el estado de la siguiente forma:
Gestión térmica: Potente y Silencioso
Aquí es donde entra en juego la combinación de ventiladores Noctua y la Corsair SF750. El objetivo es que el servidor mantenga temperaturas seguras sin que los ventiladores se disparen innecesariamente. Para eso necesitas configurar correctamente lm-sensors y las curvas de ventilación.
Detectar sensores de temperatura
# Detectar todos los sensores disponibles (responde YES a todo)
sudo sensors-detect --auto# Verificar lectura de sensoressensors
# Ver temperaturas de la GPU NVIDIA
nvidia-smi --query-gpu=temperature.gpu,fan.speed,power.draw \
--format=csv,noheader,nounits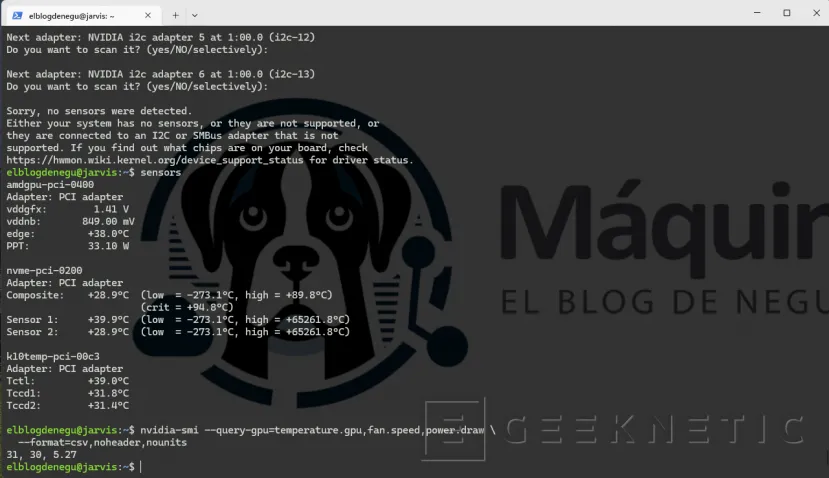
Instalar y configurar fancontrol
fancontrol permite definir curvas de temperatura/velocidad para los ventiladores controlados por PWM. Ejecuta el asistente interactivo para generar la configuración:
# Asistente de configuración (genera /etc/fancontrol)sudo pwmconfig
# Una vez configurado, activar el serviciosudo systemctl enable --now fancontrol
sudo systemctl status fancontrol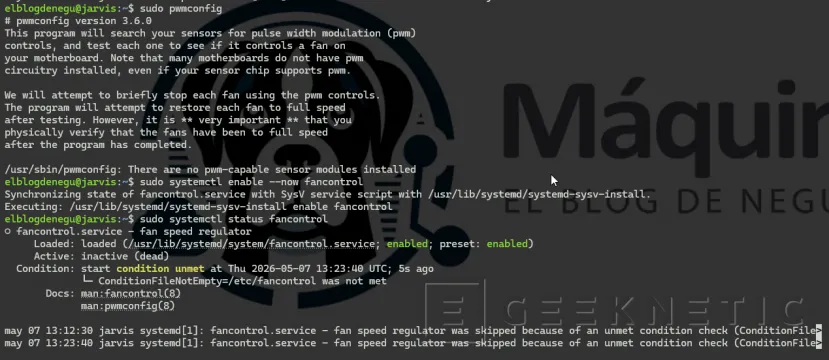
- Los ventiladores Noctua de 4 pines soportan control PWM completo. Durante el asistente
pwmconfig, el sistema probará cada canal PWM. Asegúrate de tener a mano los conectores para identificar qué ventilador responde a cada canal. Una curva conservadora: 30% hasta 50°C, subida gradual hasta 70% a 80°C, 100% solo por encima de 90°C.
Configurar límites de temperatura de la GPU
# Consultar temperatura y límites actuales de la GPUnvidia-smi -q -d TEMPERATURE
# Fijar power limit para equilibrar rendimiento y calor
# La RTX Pro 2000 tiene TDP de ~70W, ajusta según tu setupsudo nvidia-smi -pl 65
# Verificar el nuevo límite
nvidia-smi --query-gpu=power.limit --format=csv,noheader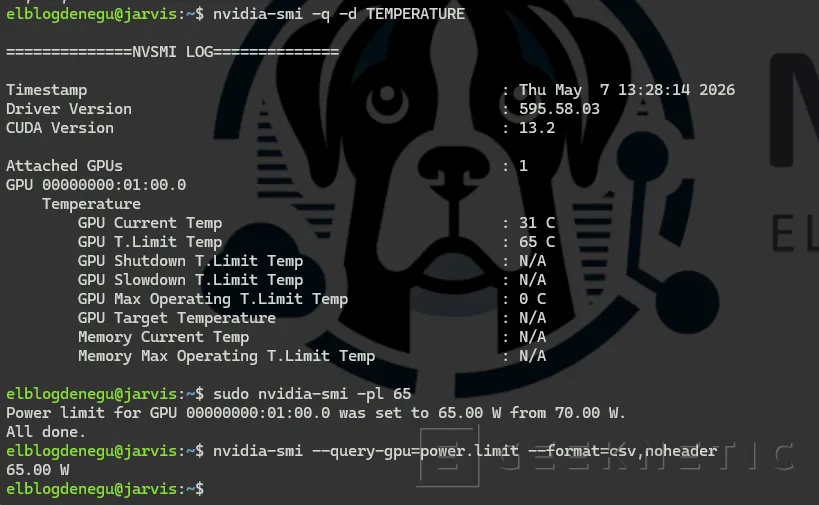
Gobernador de CPU y política de energía
El Ryzen 9 8945HX tiene una arquitectura heterogénea con núcleos P (rendimiento) y núcleos E (eficiencia). En Ubuntu Server 24.04, el kernel gestiona esto automáticamente, pero puedes afinar la política según el uso real del servidor.
Verificar el gobernador actual
# Ver gobernador actual para cada núcleo
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor | sort -u
# Ver frecuencias disponiblescpufreq-info | grep "available cpufreq governors"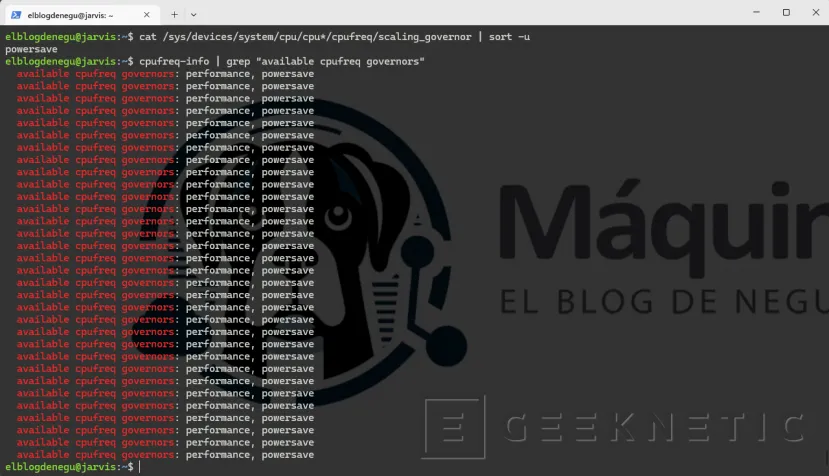
Elegir la política adecuada
Los únicos gobernadores que mi kernel/hardware admite ahora mismo son performance y powersave.
Esto es muy común en procesadores modernos que utilizan el driver intel_pstate (o el equivalente de AMD en modo activo), ya que estos drivers gestionan la frecuencia de forma interna y solo exponen esos dos perfiles.
Podemos encontrarnos estos gobernadores:
| Gobernador | Comportamiento | Recomendado para |
|---|---|---|
powersave |
Frecuencia mínima salvo necesidad | Servidor idle la mayor parte del tiempo |
performance |
Frecuencia máxima siempre | Benchmarks, carga constante alta |
schedutil |
Ajuste dinámico según scheduler | Recomendado si es posible: equilibrio óptimo |
ondemand |
Sube rápido, baja lento | Cargas con picos esporádicos |
# Establecer performance para todos los núcleos
echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
# Hacerlo persistente con cpufrequtils
echo 'GOVERNOR="performance"' | sudo tee /etc/default/cpufrequtils
sudo systemctl enable cpufrequtils
Ajustes de energía del sistema (TLP)
TLP es una herramienta de gestión avanzada de energía. Para un servidor de IA local que no corre con batería, lo interesante es su capacidad para configurar políticas de PCI Express y NVMe de forma independiente:
sudo apt install -y tlp tlp-rdwsudo tlp start
sudo tlp-stat -s # Ver estado general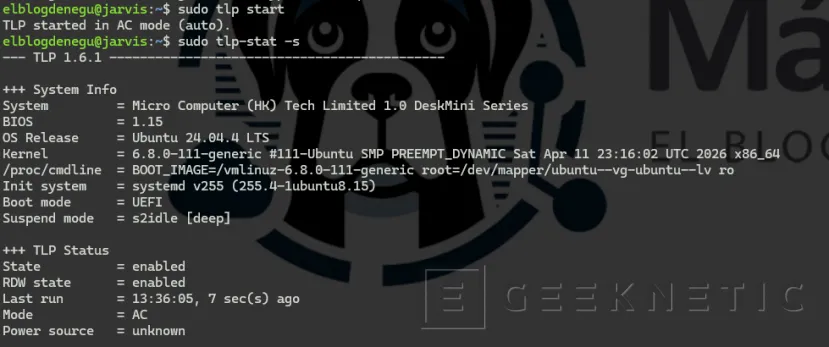
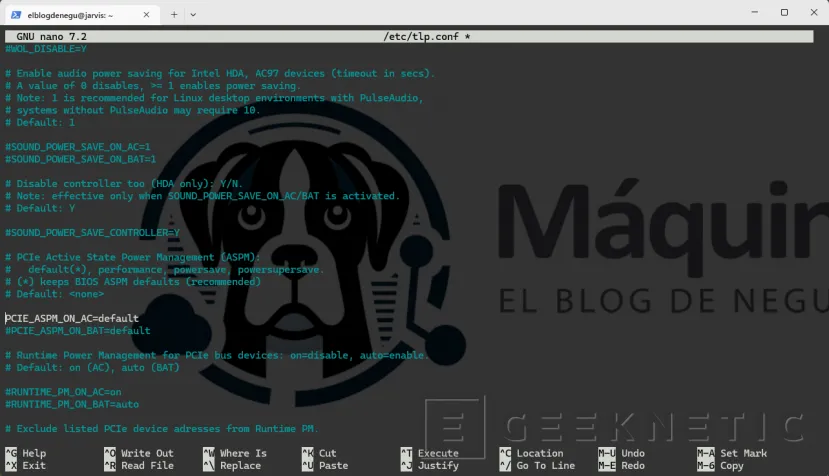
- Para servidor 24/7: En
/etc/tlp.conffijaTLP_ENABLE=1y ajustaPCIE_ASPM_ON_AC=defaultpara dejar que el kernel gestione el ASPM del PCIe. Esto evita latencias adicionales en la GPU cuando Ollama recibe peticiones.
Optimización del NVMe M.2 de 2 TB
Los modelos LLM son archivos grandes, un Llama 3.1 70B en Q4 ocupa unos 40 GB. Si Ollama tiene que cargar modelos desde un NVMe lento o mal configurado, el tiempo hasta la primera respuesta se dispara. Estos ajustes marcan la diferencia.
Verificar el estado del NVMe
# Identificar el dispositivo NVMelsblk -d -o NAME,SIZE,MODEL,ROTAnvme list
# Estado SMART del discosudo nvme smart-log /dev/nvme0# Temperatura del NVMe
sudo nvme smart-log /dev/nvme0 | grep "temperature"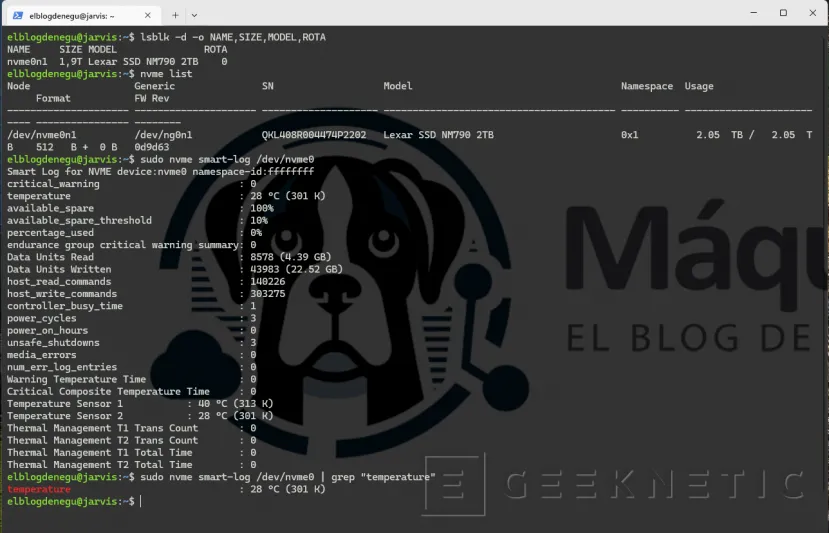
Activar el scheduler io_uring
# Verificar scheduler actual del NVMecat /sys/block/nvme0n1/queue/scheduler
# El scheduler 'none' es óptimo para NVMe (cola de hardware directa)
echo none | sudo tee /sys/block/nvme0n1/queue/scheduler
# Hacerlo persistente con udev
echo 'ACTION=="add|change", KERNEL=="nvme[0-9]*", \
ATTR{queue/scheduler}="none"' | \
sudo tee /etc/udev/rules.d/60-nvme-scheduler.rules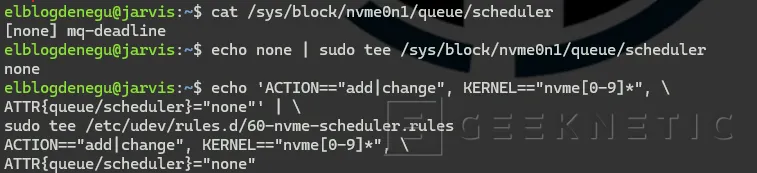
Ajustar opciones de montaje para rendimiento
# Añadir noatime a la partición raíz en /etc/fstab
# Busca la línea de tu partición raíz y añade 'noatime'# Ejemplo:
UUID=xxxx-xxxx / ext4 defaults,noatime 0 1
# noatime evita escrituras de timestamps en cada lectura de archivo
# Para archivos de modelos grandes esto supone cientos de escrituras menos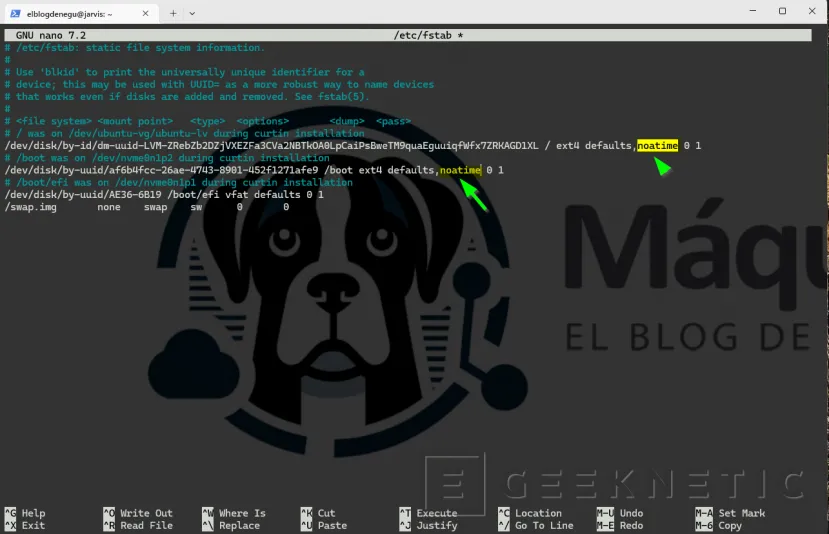
Directorio de modelos en NVMe dedicado
# Crear directorio dedicado para modelos de IAsudo mkdir -p /opt/ai/models
sudo chown $USER:$USER /opt/ai/models
# Enlace simbólico para Ollama (lo usaremos en el paso siguiente)
mkdir -p ~/.ollamaln -sf /opt/ai/models ~/.ollama/models
Docker con soporte GPU (NVIDIA Container Toolkit)
Docker es el entorno de laboratorio por excelencia para IA local. Con el NVIDIA Container Toolkit, los contenedores pueden acceder directamente a la GPU sin ninguna configuración adicional por contenedor.
Instalar Docker Engine
# Añadir repositorio oficial de Docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | \
sudo gpg --dearmor -o /usr/share/keyrings/docker.gpg
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker.gpg] \
https://download.docker.com/linux/ubuntu noble stable" | \
sudo tee /etc/apt/sources.list.d/docker.listsudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io \
docker-buildx-plugin docker-compose-plugin
# Añadir tu usuario al grupo docker (evitar sudo)sudo usermod -aG docker $USER
newgrp docker
Instalar NVIDIA Container Toolkit
# Repositorio NVIDIA para el toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listsudo apt update
sudo apt install -y nvidia-container-toolkit
# Configurar Docker para usar el runtime NVIDIA
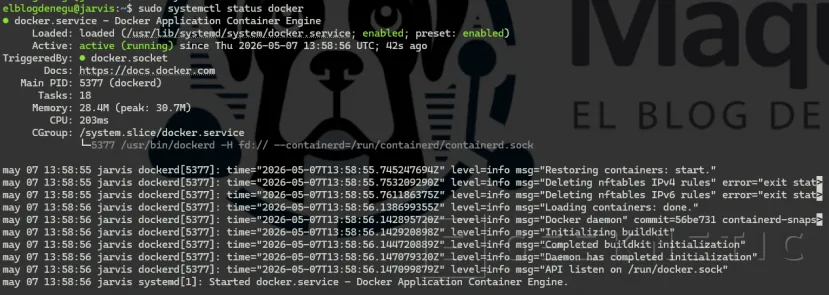
sudo nvidia-ctk runtime configure --runtime=dockersudo systemctl restart docker
Comprobar estado:
Verificar acceso GPU desde contenedor
# Test rápido: nvidia-smi dentro de un contenedor
docker run --rm --gpus all nvidia/cuda:12.6.0-base-ubuntu24.04 nvidia-smi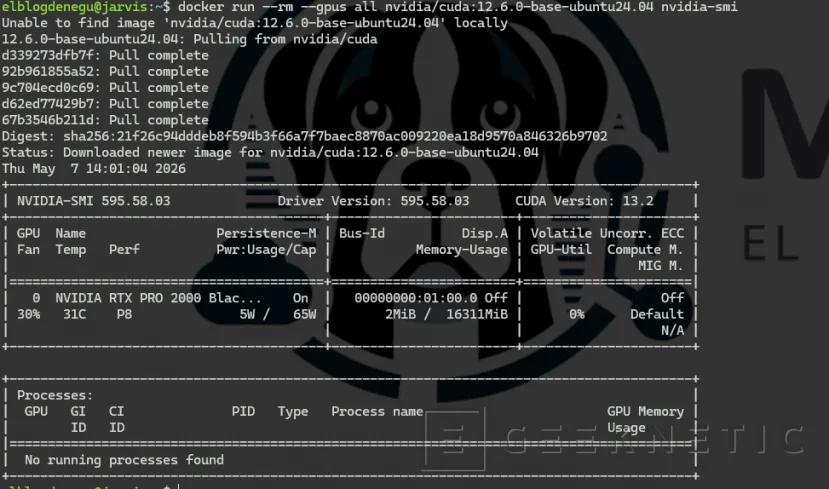
Si ves la salida de nvidia-smi con tu RTX Pro 2000, el toolkit está funcionando. A partir de aquí, cualquier contenedor que lances con --gpus all tendrá acceso completo a la GPU.
Ollama: el motor de IA local
Con el stack CUDA listo y Docker configurado, es el momento de instalar Ollama. Es el gestor de modelos LLM más práctico para Linux, descarga, gestiona y sirve modelos con una API compatible con OpenAI.
Instalación de Ollama
# Instalador oficial (instala el binario y el servicio systemd)
curl -fsSL https://ollama.com/install.sh | sh# Verificar instalación
ollama --versionsystemctl status ollama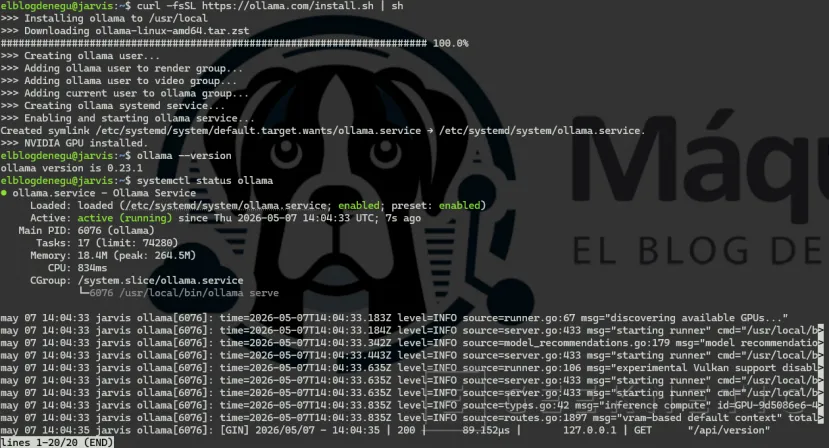
Configurar Ollama para acceso en red
Por defecto, Ollama solo escucha en localhost. Si quieres acceder desde otras máquinas de la red local, edita el servicio:
# Editar el servicio de Ollamasudo systemctl edit ollama
# Añadir en la sección [Service]:[Service]Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_MODELS=/opt/ai/models"Environment="OLLAMA_NUM_PARALLEL=2"
# Recargar y reiniciarsudo systemctl daemon-reloadsudo systemctl restart ollama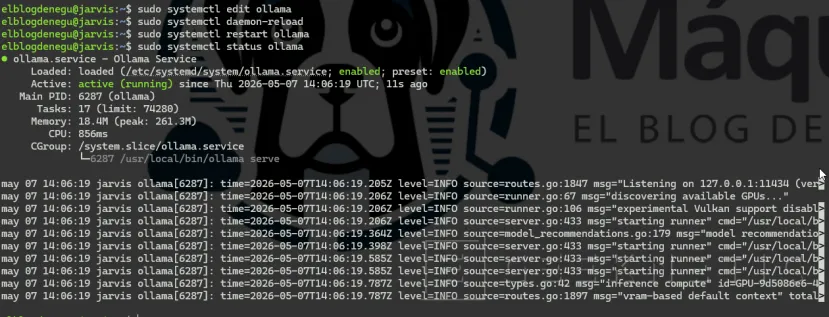
Variables de entorno útiles para Ollama
| Variable | Valor ejemplo | Efecto |
|---|---|---|
OLLAMA_HOST |
0.0.0.0 |
Escucha en todas las interfaces |
OLLAMA_MODELS |
/opt/ai/models |
Directorio de modelos personalizado |
OLLAMA_NUM_PARALLEL |
2 |
Peticiones simultáneas (según VRAM) |
OLLAMA_MAX_LOADED_MODELS |
2 |
Modelos en memoria a la vez |
CUDA_VISIBLE_DEVICES |
0 |
GPU específica para Ollama |
Descargar y probar el primer modelo
# Descargar un modelo de prueba (Llama 3.2 3B, ~2GB)ollama pull llama3.2:3b
# Ejecutar una inferencia de prueba
ollama run llama3.2:3b "Explica qué es una NPU en 2 frases"
# Ver uso de VRAM durante inferencia (en otra terminal)
watch -n 1 nvidia-smi --query-gpu=memory.used,utilization.gpu \
--format=csv,noheader,nounits# Listar modelos instaladosollama list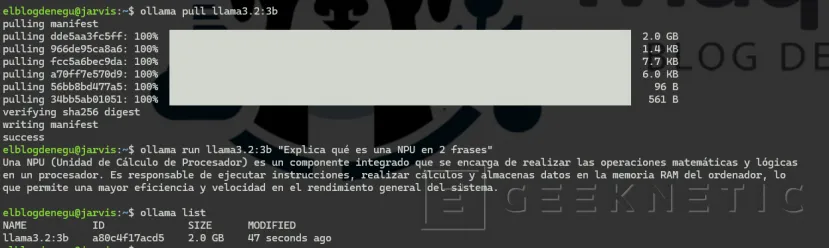

- Con 16 GB de VRAM tenemos margen para modelos grandes.
llama3.1:70b-instruct-q4_K_M(~40 GB) requiere offloading a RAM, pero con 64 GB DDR5 funciona bien. Para uso exclusivo en GPU:qwen2.5:14bomistral:7bcorren completamente en VRAM.
Verificar que Ollama usa la GPU
# Mientras Ollama procesa una petición, mira nvidia-sminvidia-smi
# En el campo "Processes" debe aparecer el proceso "ollama_llm"
# con el número de MiB de VRAM que está usando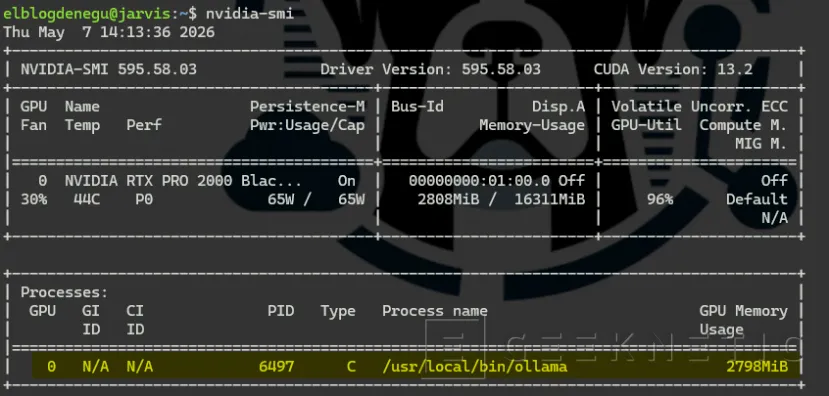
Verificación final y checklist
Antes de dar el servidor por configurado (podríamos compilar opcionalmente, por ejemplo, Driver NPU Ryzen AI (XDNA)), vamos a repasar la lista. Cada punto debería devolver una respuesta limpia sin errores.
# 1. Sistema actualizado
sudo apt list --upgradable 2>/dev/null | grep -v Listing
# 2. Driver NVIDIA activonvidia-smi | head -10# 3. CUDA funcionalnvcc --version
# 4. Docker con GPU
docker run --rm --gpus all nvidia/cuda:12.6.0-base-ubuntu24.04 nvidia-smi
# 5. Ollama activo y viendo la GPUsystemctl is-active ollama
curl http://localhost:11434/api/tags# 6. Sensores de temperatura
sensors | grep -E "Package|Core 0|GPU"# 7. Gobernador de CPU
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor# 8. Scheduler NVMe
cat /sys/block/nvme0n1/queue/scheduler# 9. Espacio en discodf -h /opt/ai/models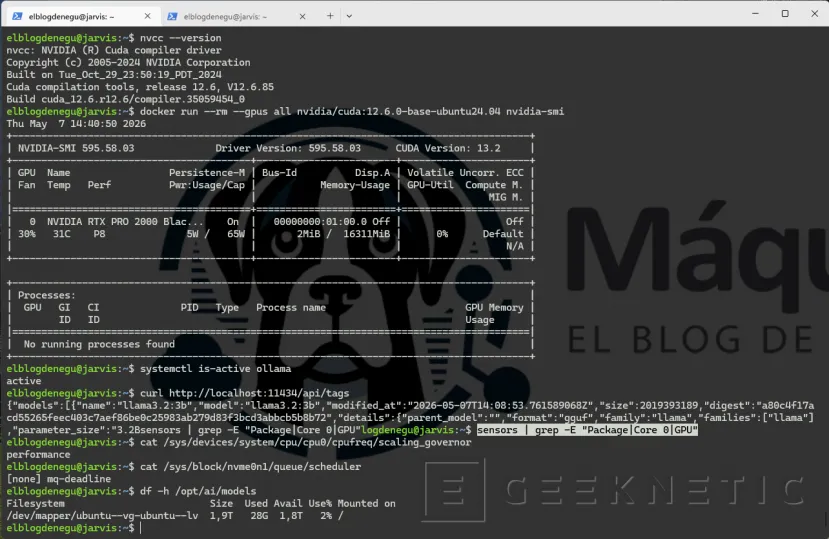
Checklist de servicios en arranque
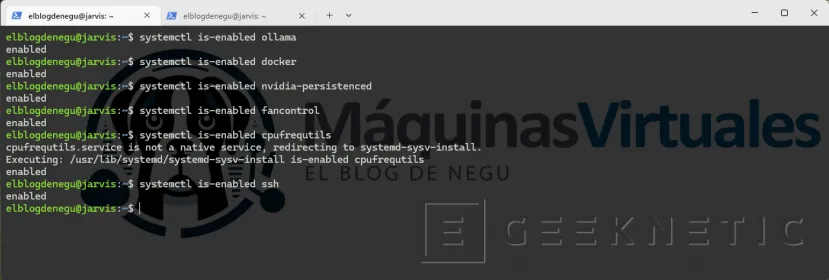
systemctl is-enabled ollama→ enabledsystemctl is-enabled docker→ enabledsystemctl is-enabled nvidia-persistenced→ enabledsystemctl is-enabled fancontrol→ enabledsystemctl is-enabled cpufrequtils→ enabledsystemctl is-enabled ssh→ enabled
Trabajando con IA Local
Llegados aquí, el servidor ya no es una instalación fresca. Es un sistema que sabe lo que tiene que hacer, gestionar su propia temperatura, dosificar energía según la carga, mantener los drivers estables entre reinicios y servir modelos a través de Ollama sin que nadie tenga que supervisarlo. Todo eso corriendo en silencio, sin interfaz gráfica que consuma recursos, sin servicios innecesarios compitiendo por RAM.
La post-instalación es el trabajo invisible que separa un servidor funcional de un servidor fiable. La diferencia no se nota el primer día, se nota tres meses después, cuando el sistema sigue respondiendo igual que el día uno y no has tenido que tocarlo desde entonces.
A partir de aquí, el hardware está exprimido desde el lado del software base. Lo que viene es construir encima, Open WebUI para tener una interfaz accesible, pipelines de AIOps para automatizar tareas de monitorización, y si tienes el Minisforum con Ryzen AI como en el ejemplo, explorar qué carga puedes moverle a la NPU para liberar GPU. El servidor está listo.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







